Projects
These are some of my recent and active coding projects, research-related or otherwise. Check my public github for more.
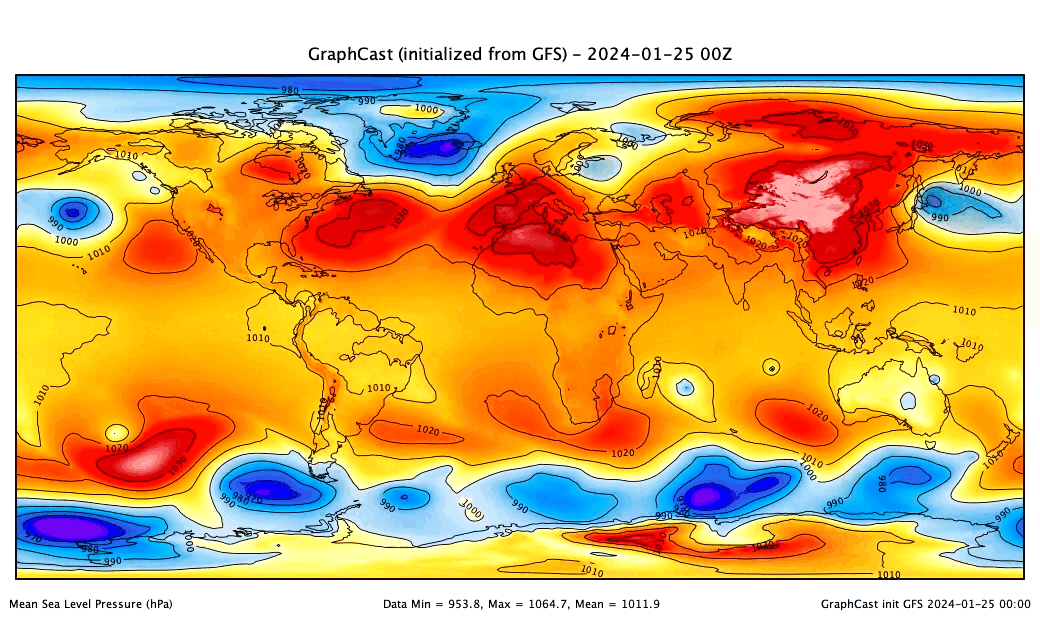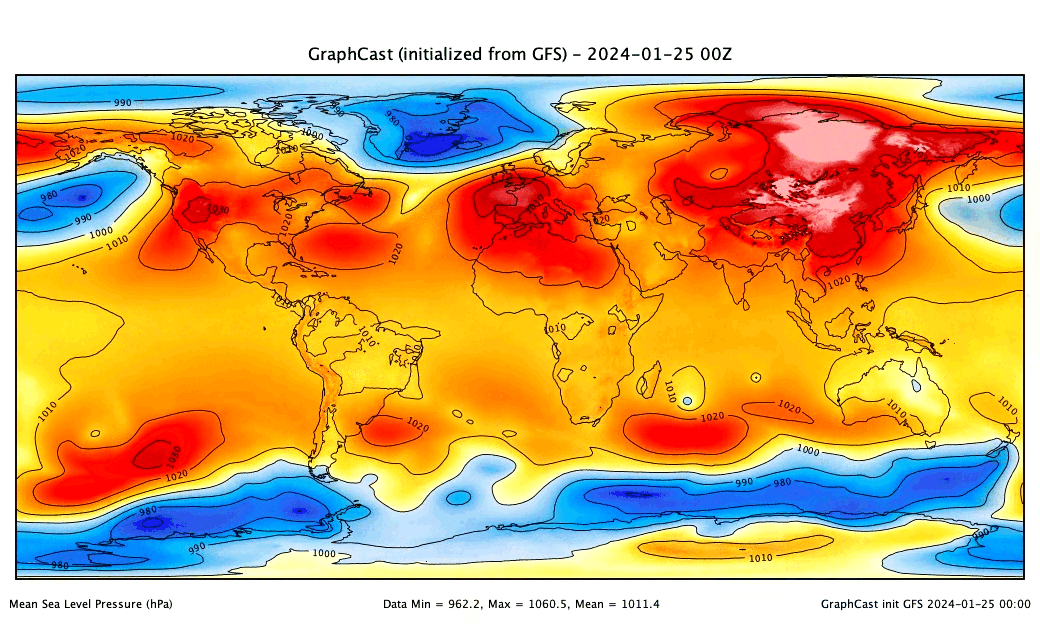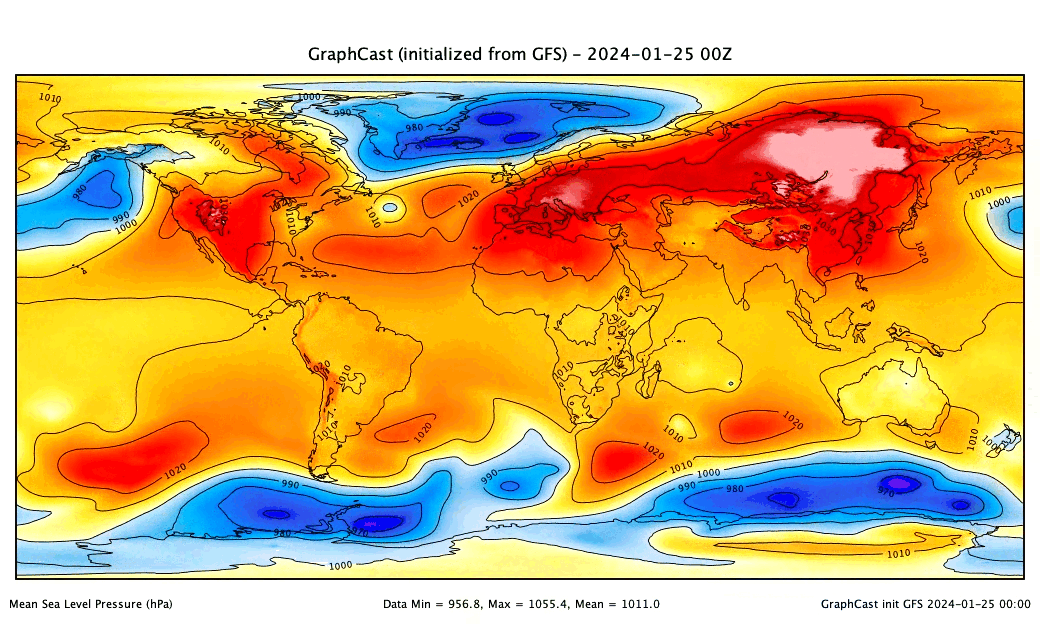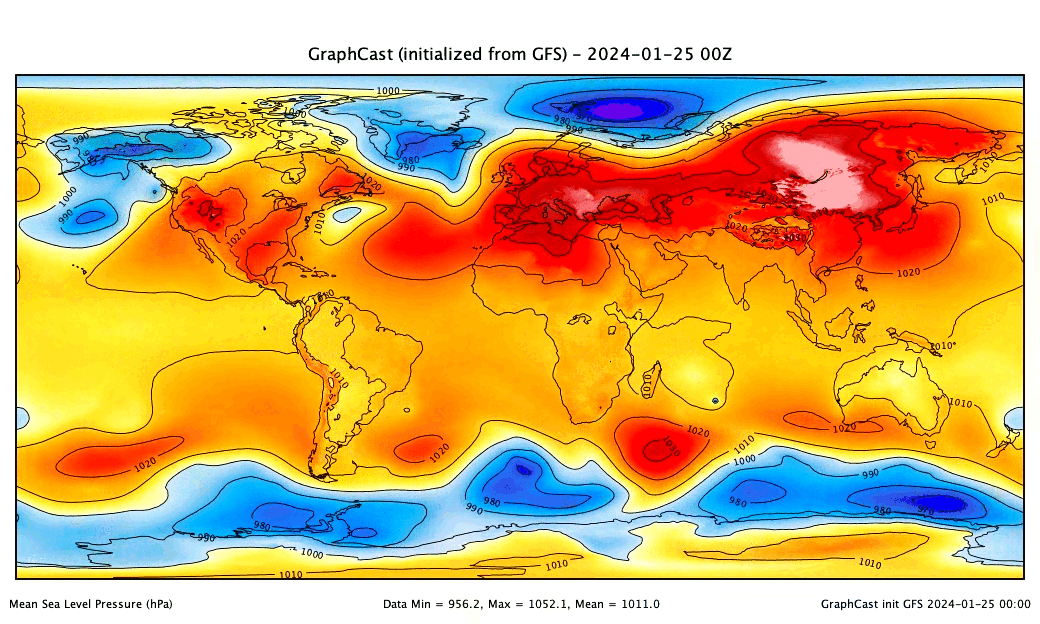
ai-models-for-all



In 2023, "AI-NWP" models (deep learning surrogates of numerical weather prediction systems) took the meteorology world by storm. A number of groups - mostly big tech companies - trained versions of these models and released both their code and pre-trained weights for users to both re-produce their results and generate real world forecasts. However, to do this users need non-trivial skills and experience in MLOps and working with both AI models and weather datasets.
ai-models-for-all solves this problem by wrapping the ecmwf-labs/ai-models package in a framework that runs published AI models end-to-end on a serverless framework. Users only need to provide account credentials; then, generating a state-of-the-art AI-NWP forecast is as easy as entering a single command in the terminal... and the forecast runs in minutes for less than a cup of coffee!
Highlights
- Provides interface for PanguWeather, FourCastNet, and GraphCast.
- Runs on Modal serverless platform and integrates with Google Cloud Platform for output archival.
- Allows users to initialize forecasts from either ERA-5 or GFS analyses as published in near-real-time.
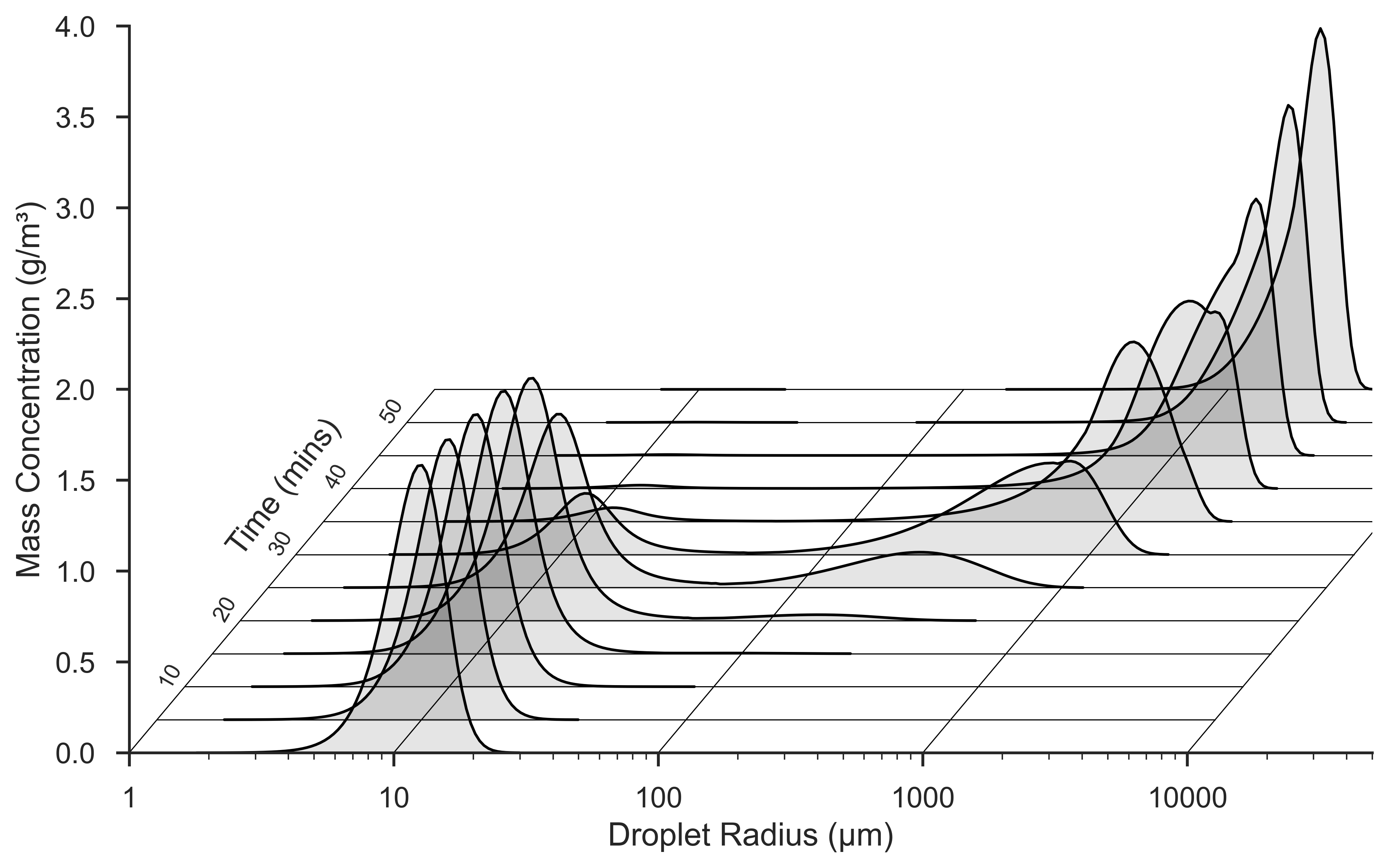
Coad.jl


Coad.jl is an optimized, Julia-native implementation of the numerical solver proposed in Bott (1998), "A Flux Method for the Numerical Solution of the Stochastic Collection Equation". This solver computes the evolution of an arbitrary, binned droplet size distribution due to collison and coalescence, given several options for a collision kernel, following the SCE:
$$\frac{\partial n(x,t)}{\partial t} = \int\limits_{x_0}^{x_1} n(x_c, t)K(x_c,x')n(x', t)\,dx' - \int\limits_{x_0}^\infty n(x,t)K(x, x')n(x',t)\, dx'$$
Highlights
- Simple but well-structured Julia package with limited dependencies.
- Model performance exceeds original FORTRAN77 implementation thanks to seamless multi-threading.

gcpy
Starting as an independent project and now owned and maintained by the GEOS-Chem Support Team, GCPy was an effort to modernize the IDL-based toolkit which many GEOS-Chem users leveraged to support their research. GCPy makes it significantly easier for members of the research community to build complex analyses and workflows using model outputs, and ultimately connect these data to other libraries within the scientific Python ecosystem.
xbpch
![]()
![]()

Up until v11-03 of GEOS-Chem (unreleased), all of the output generated by that model is written in a proprietary binary output format. While some community tools existed to help process this format into more convenient forms, they tended to be a bit slow and cumbersome to incorporate into my workflow. So, in xbpch I built a core set of functionality to allow users to easily ingest this data into xarray. Additionally, xbpch has the option to defer reading data from disk, which dramatically increases analysis performance, particularly when data is split across multiple files (as is the case for some diagnostics).
Highlights
- Written in Python and accelerated with dask
- Simple emulation of xarray interface for reading datasets
- Includes simple command line tool for batch processing of bpch to NetCDF format
- Complete documentation with introduction to xarray and usage examples.
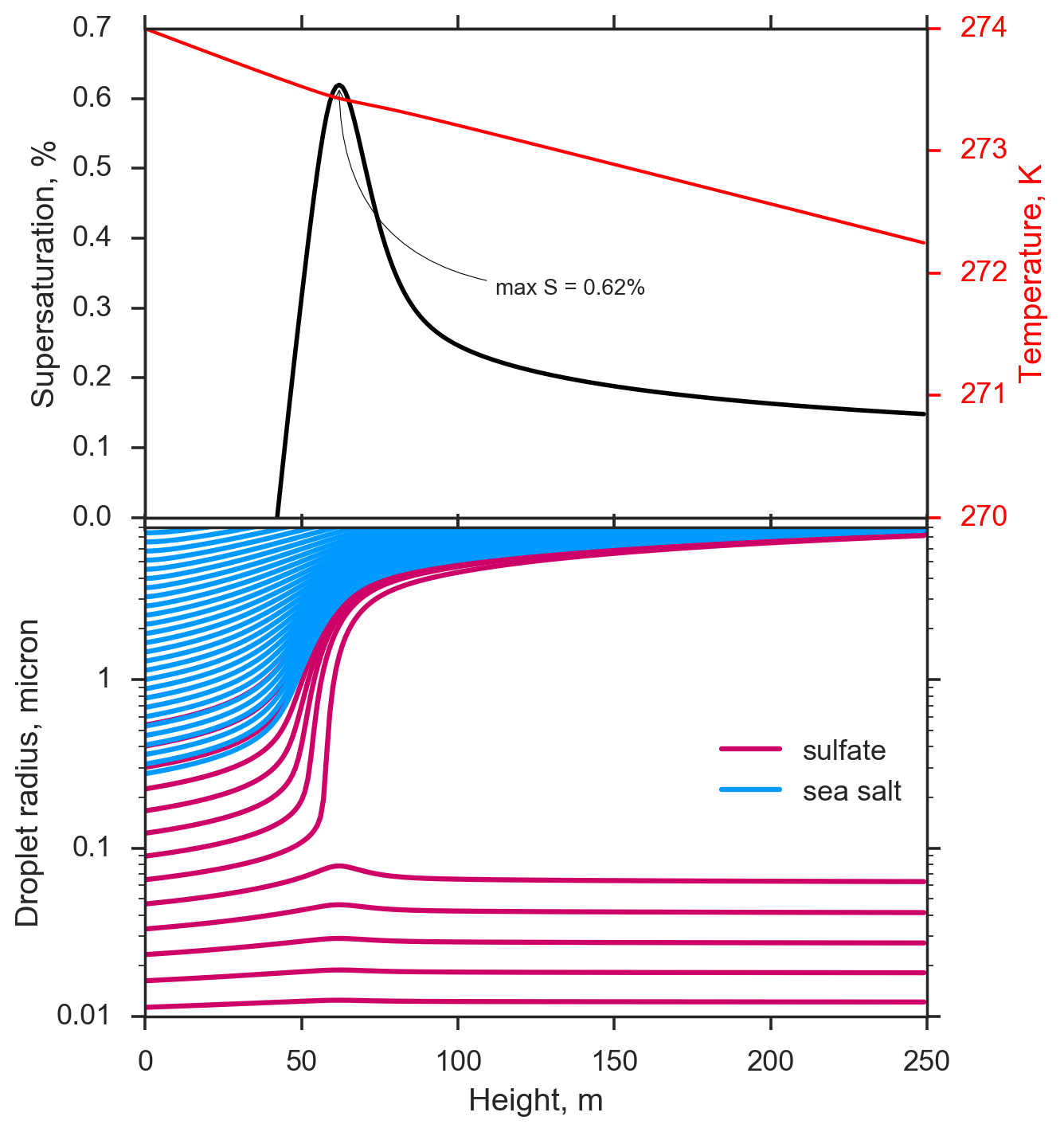
pyrcel

![]()

One of the most fundamental tools in the arsenal of an atmospheric physicist studying cloud phenomena is the parcel model, a 0-dimensional representation of an ascending plume of air. Parcel models model the thermodynamic evolution of such a plume, and can be used to studying many physical phenomena. To aid my research in developing novel aerosol-cloud interaction schemes for atmospheric models, I've developed an extensible warm-cloud parcel model with a simple physico-chemical representation of droplets. With this tool, one can simulate droplet activation dynamics in detail, and compare against parameterizations or observations from the field and laboratory.
Highlights
- Written in Python, with either a numba or Cython core for solving model equations
- Library, command-line, and file I/O interfaces for running simulations
- Multiple output formats and options
- Includes library of activation schemes, thermodynamic functions, and aerosol/droplet size distribution tools
experiment
This library contains a utility for working with ensembles of numerical model output. It's intended to be an extension to xarray which can be used either interactively in notebooks or simple script, or as part of build systems to configure and permit access to large datasets on disk. I've previously used this library to help automate processing of very large (multi-terabyte) GEOS-Chem, CESM, and CAM-Chem simulations archived on the cluster. experiment implements parallel processing through dask to help handle and speed-up the processing of these large ensemble datasets.
Highlights
- Built on top of Python/xarray/dask
- Serialize configured experiments for storing alongside data
- Tested on both distributed and HPC computing environments
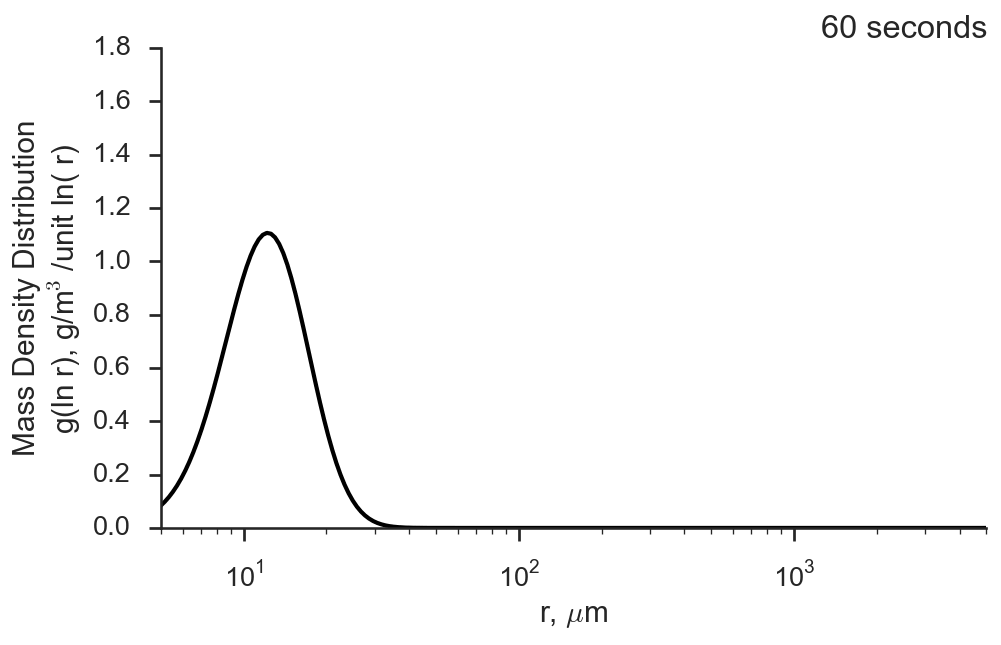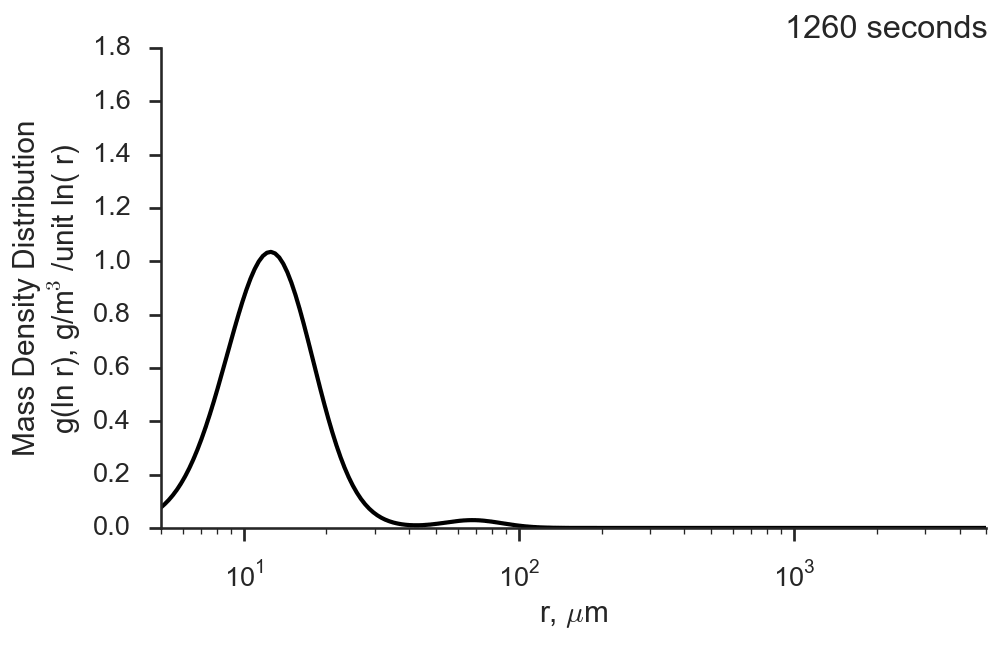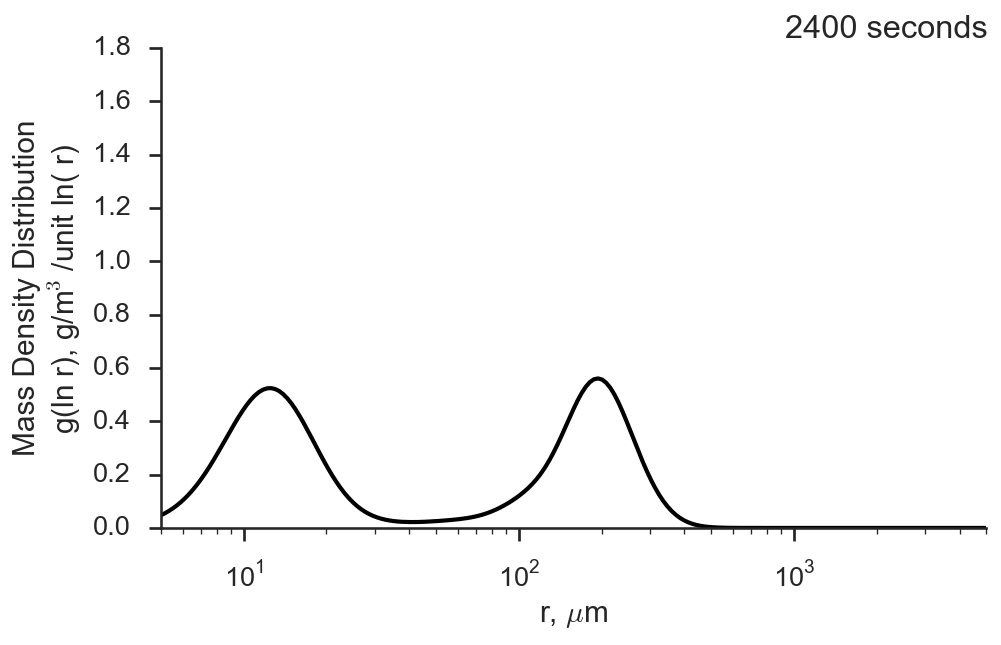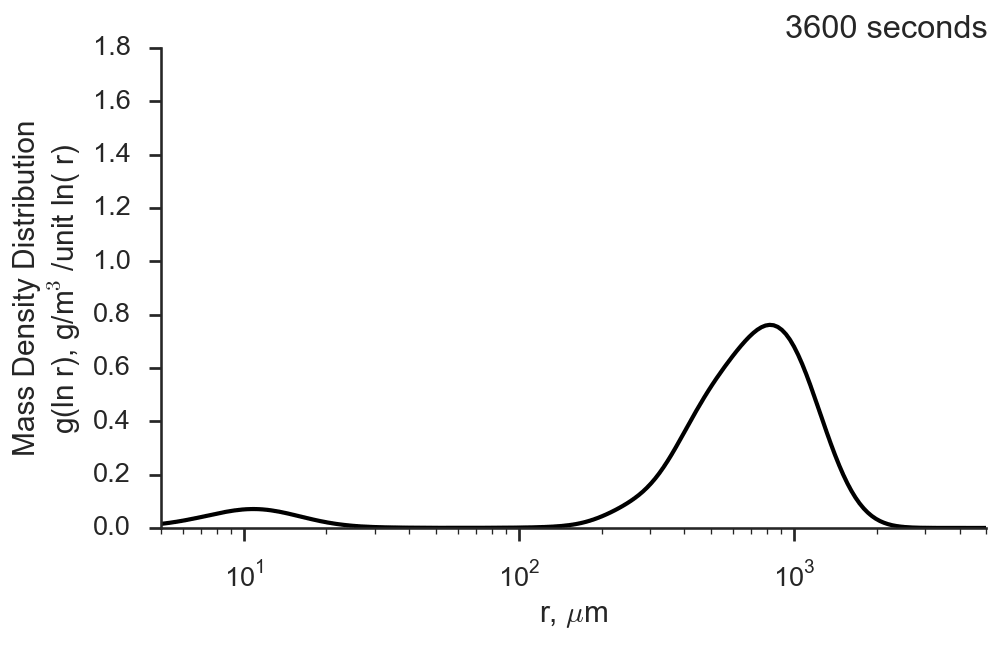
superdroplet
Capturing the physics of how droplets interact within a cloud and how their size distribution changes over time is a challenging problem for atmospheric modelers. Droplet collision and coalescence is often very crudely parameterized in global models, but even detailed spectral bin models have issues with faithfully capturing their effects. This model implements the Superdroplet method using an object-oriented framework to solve the stochastic collision/coalescence equation and evolve a droplet size distribution over time for some simple (non-turbulent) collision kernels.
Highlights
- Multiple versions - Python+Cython, C++, Fortran 2008, Julia, and Chapel (
coming soon ) - Straightforward configuration with ASCII output (consistent between implementations)
- Go-to "hello, world" application for OOP/scientific computing
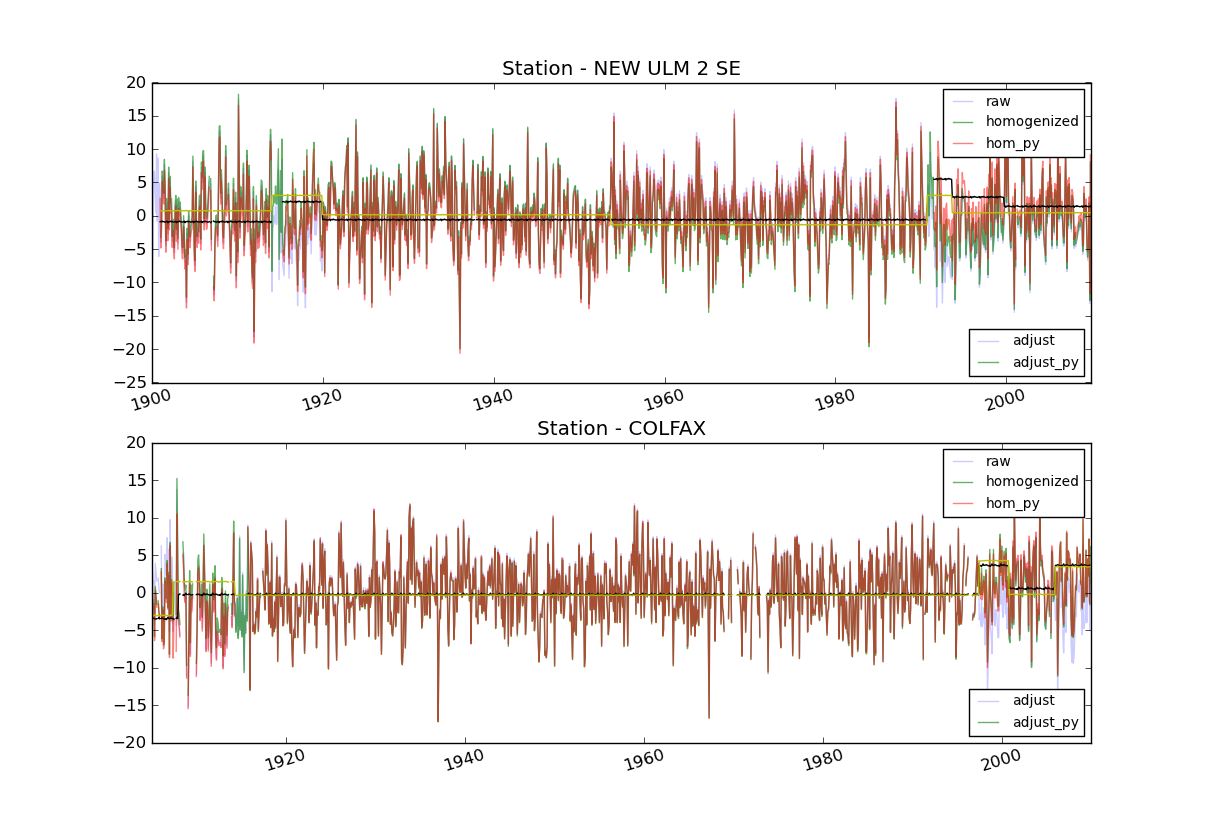
ccf-homogenization
In 2011, I participated in the Google Summer of Code under the mentorship of the Climate Code Foundation. My goal was to open-source and de-obfuscate a complex piece of Fortran code that quality-controlled the United States' historical surface temperature record by applying statistical analyses to detect breakpoints and anomalous trends in the network of station observations. We had broader goals of developing alternative homogenization algorithms (building a library) and of building a platform for meta-analysis of the homogenization technique for assessing statistical uncertainty, but the initial goal proved very daunting and time-consuming.
Critically, this project was a wake-up call in how important software engineering is when developing scientific codes - especially those in operational or production contexts. This project identified several major bugs in the original PHA algorithm, which ultimately contributed to a small increase in our best estimate of how much the US warmed over the past century!